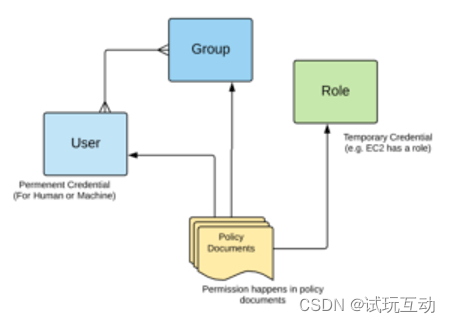
查看unsigned 的原因
GET /_cluster/health
GET _cluster/allocation/explain?pretty
the node is above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=95%], using more disk space than the maximum allowed [95.0%], actual free: [4.055101177689788%]
解決:磁盤擴容或定期刪除無用數據(設定數據保存時間)
DELETE /indexName
通常如果磁盤滿了,ES為了保證集群的穩定性,會將該節點上所有的索引設置為只讀。ES 7.x版本之后當磁盤空間提升后可自動解除,但是7.x版本之前則需要手動執行下面的API來解除只讀模式:
PUT indexName/_settings
{"index": {"blocks": {"read_only_allow_delete": "false"}}
}
failure IllegalArgumentException[number of documents in the index cannot exceed 2147483519
常見的?解決:向新索引中寫入數據(按天生成新索引),并設置分片大小
cannot allocate because a previous copy of the primary shard existed but can no longer be found on the nodes in the cluster
解決:找到掉線的故障原因,并將節點重新加入集群,等待分片恢復
PUT /_cluster/settings
{"transient" : {"cluster.routing.allocation.include._ip": "IP address"}
}
node does not match index setting [index.routing.allocation.require] filters [temperature:“warm”,_id:“comdNq4ZSd2Y6ycB9Oubsg”]
解決:重新設置索引的冷熱屬性,和節點保持一致;如果重新設置節點屬性,則需要重啟節點。可以通過API來修改索引所需要分配節點的溫度屬性
PUT /indexName/_settings
{"index": {"routing": {"allocation": {"require": {"temperature": "warm"}}}}
}
cannot allocate because all found copies of the shard are either stale or corrupt
解決:使用reroute api
PUT /_cluster/reroute
{"commands": [{"allocate_stale_primary": {"index": "IndexName","share": "0","node": "nodeName","accept_data_loss": true}}]
}
elasticsearch should。6、未分配的分片太多,導致達到了分片恢復的最大閾值,其他分片需要排隊等待
reached the limit of incoming shard recoveries [2], cluster setting [cluster.routing.allocation.node_concurrent_incoming_recoveries=2] (can also be set via [cluster.routing.allocation.node_concurrent_recoveries])
解決:使用cluster/settings調大分片恢復的并發度和速度
PUT /_cluster/settings
{"persistent": {"indices.recovery.max_bytes_per_sec": "200mb","cluster.routing.allocation.node_concurrent_recoveries":5,"cluster.routing.allocation.cluster_concurrent_rebalance":5}
}
參考整理自:Elasticsearch集群規劃及性能優化實踐(筆記)
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态